Abstract
Problem
 (a) Given an egocentric video and a query image of an object, the goal is to localize the last occurrence of the query object in the video. (b) Unlike third-person videos, egocentric videos undergo abrupt viewpoint changes due to the camera wearer’s movements. (c) These viewpoint changes introduce significant challenges in VQL, including variations in object appearance across perspectives and partial visibility when objects move out of the frame. For example, the appearance of a banana changes depending on the viewpoint, and a bottle becomes partially visible.
(a) Given an egocentric video and a query image of an object, the goal is to localize the last occurrence of the query object in the video. (b) Unlike third-person videos, egocentric videos undergo abrupt viewpoint changes due to the camera wearer’s movements. (c) These viewpoint changes introduce significant challenges in VQL, including variations in object appearance across perspectives and partial visibility when objects move out of the frame. For example, the appearance of a banana changes depending on the viewpoint, and a bottle becomes partially visible.
Architecture
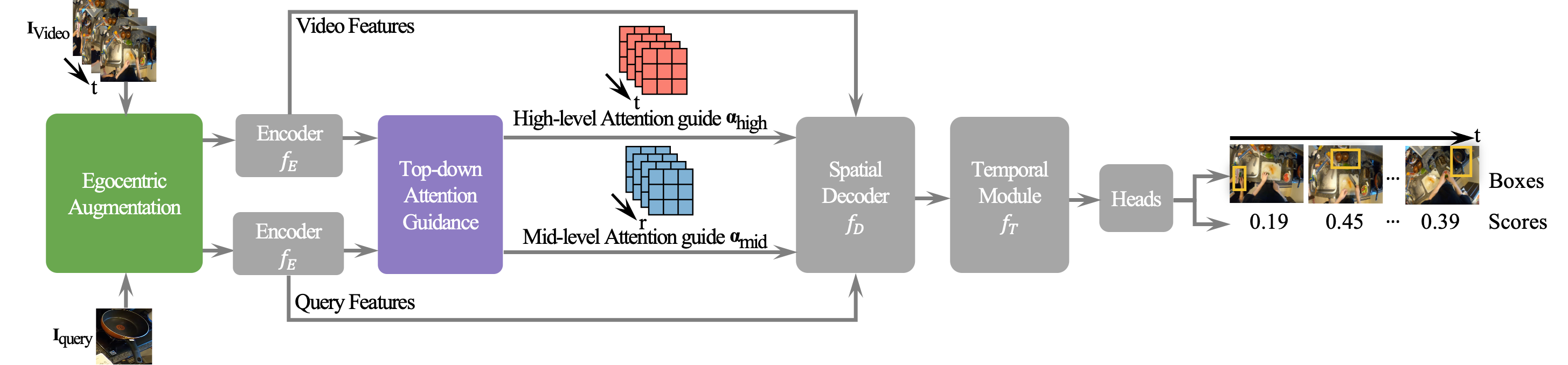 Given a video and a query image, we extract feature vectors using a pre-trained visual encoder. We feed the feature vectors through a spatial decoder, followed by a temporal module and a prediction head outputs per-frame bounding boxes and scores.
Given a video and a query image, we extract feature vectors using a pre-trained visual encoder. We feed the feature vectors through a spatial decoder, followed by a temporal module and a prediction head outputs per-frame bounding boxes and scores.
Top-down Attention Guidance
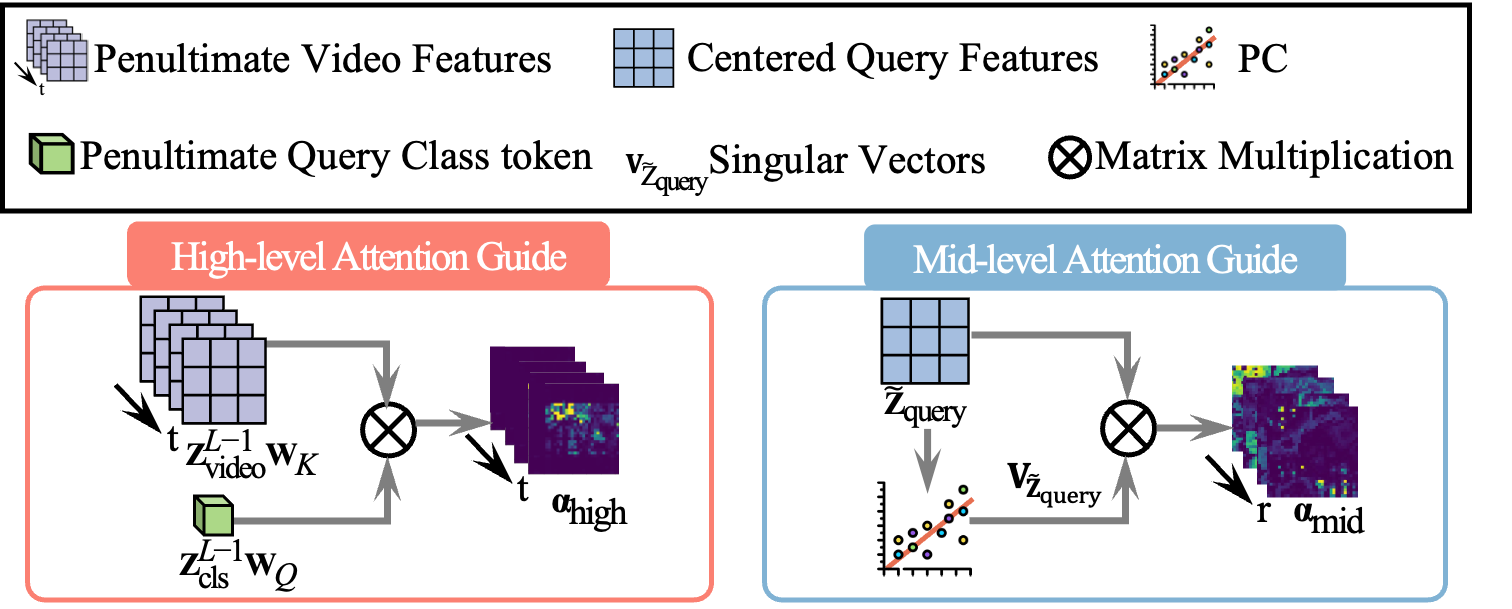 TAG guides the spatial decoder’s attention using a high-level cue to capture the overall query context and a mid-level cue to enhance the understanding of fine-grained object parts.
TAG guides the spatial decoder’s attention using a high-level cue to capture the overall query context and a mid-level cue to enhance the understanding of fine-grained object parts.
Egocentric Augmentation based Consistency Training
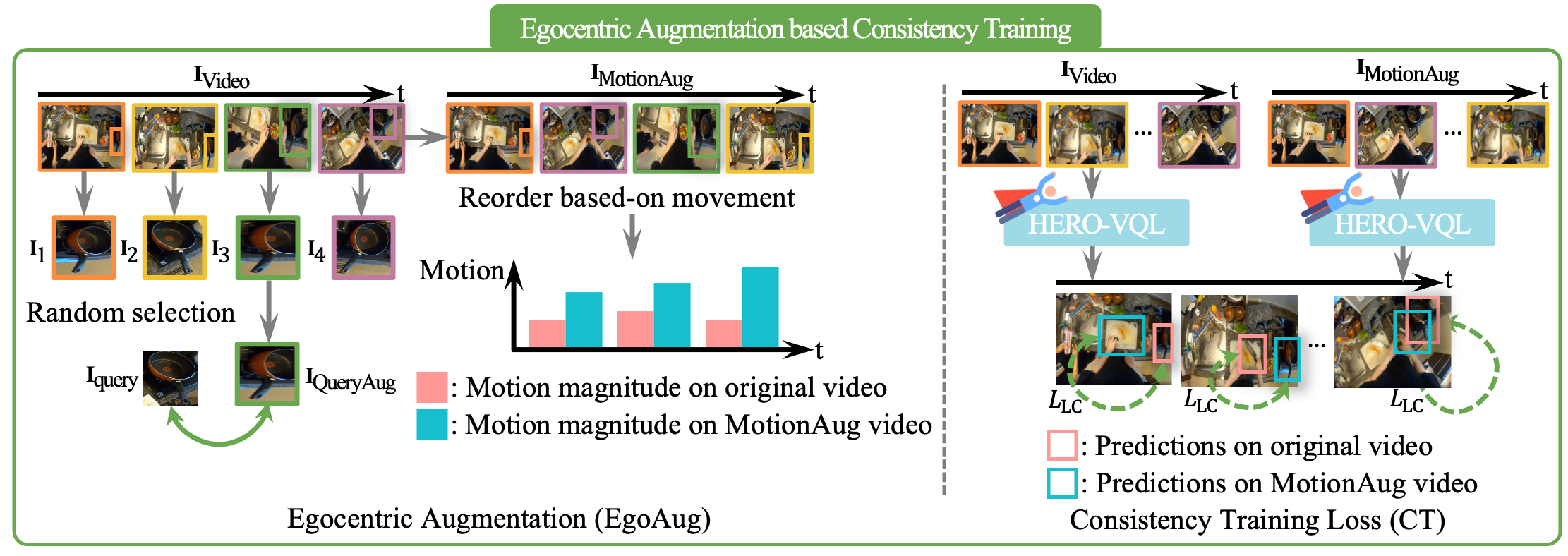 To enable robust matching, we replace the query image with a randomly selected corresponding object instance from the ground-truth. We reorder video frames based on object movement magnitude to simulate abrupt viewpoint changes. We also enforce temporal consistency, improving localization stability in egocentric videos.
To enable robust matching, we replace the query image with a randomly selected corresponding object instance from the ground-truth. We reorder video frames based on object movement magnitude to simulate abrupt viewpoint changes. We also enforce temporal consistency, improving localization stability in egocentric videos.
Experiments
Comparison with state-of-the-art on VQ2D
We report the tAP25, stAP25, recovery (Rec. %), and the success rate (Succ.) on the validation set and the test set.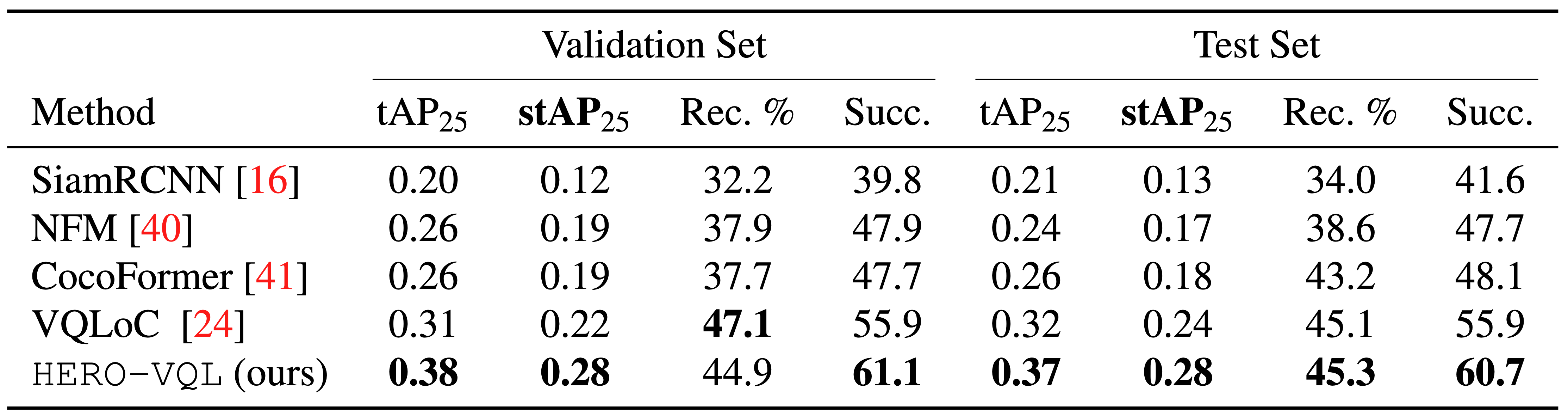
Ablation study
To validate the effect of each component, we show the results on the VQ2D validation set. We report tAP25, stAP25, recovery (Rec. %), and success rate (Succ.) as percentages.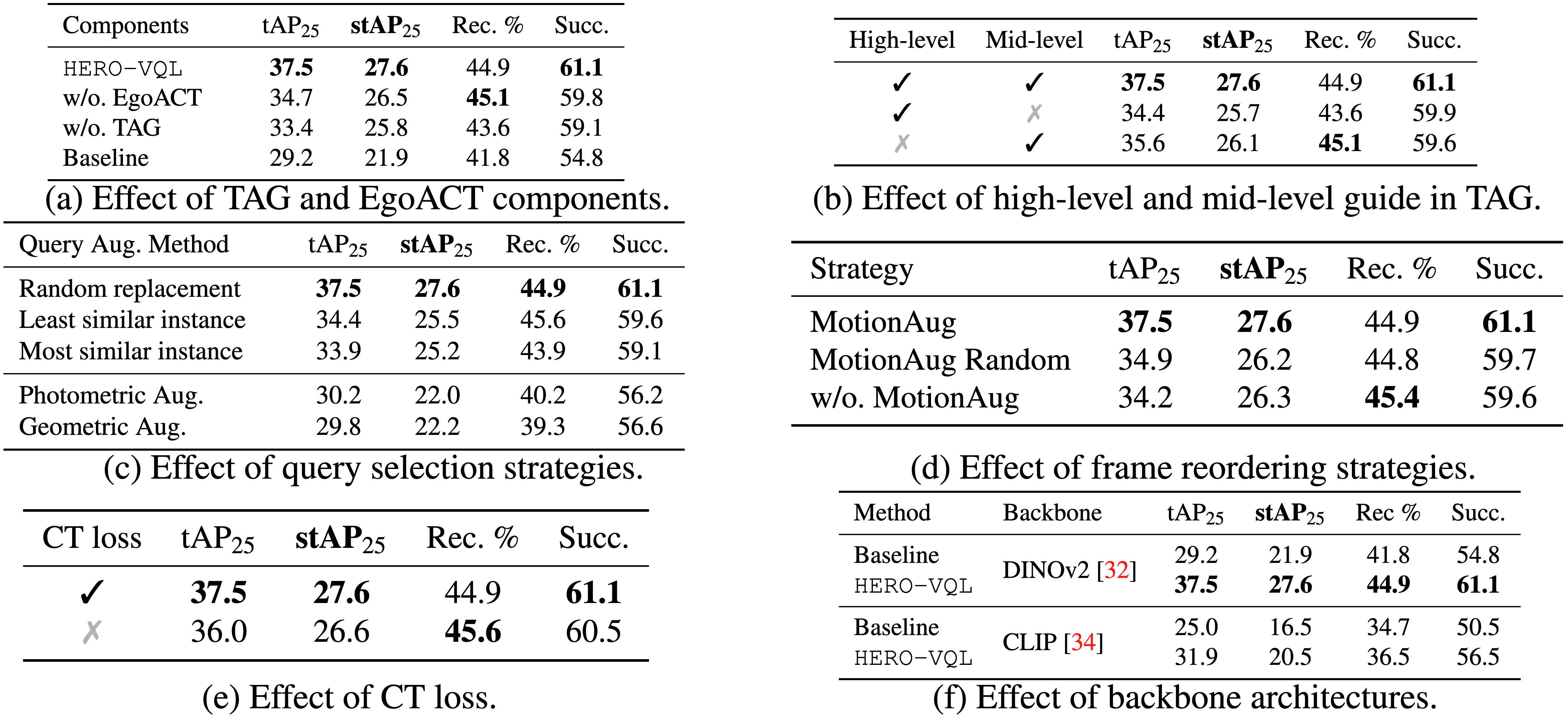
Visualization of TAG
 We show the query image and four frames from each video with TAG’s high-level and mid-level attention guides. The high-level attention guide emphasize the region of the target object and the mid-level attention guide attends to specific object parts in the query feature. They improve the model’s ability to localize objects accurately, under varying perspectives or partial visibility.
We show the query image and four frames from each video with TAG’s high-level and mid-level attention guides. The high-level attention guide emphasize the region of the target object and the mid-level attention guide attends to specific object parts in the query feature. They improve the model’s ability to localize objects accurately, under varying perspectives or partial visibility.
Citation
@inproceedings{chang2025herovql,
title={HERO-VQL: Hierarchical, Egocentric and Robust Visual Query Localization},
author={Chang, Joohyun and Hong, Soyeon and Lee, Hyogun and Ha, Seong Jong and Lee, Dongho and Kim, Seong Tae and Choi, Jinwoo},
booktitle={BMVC},
year={2025},
}